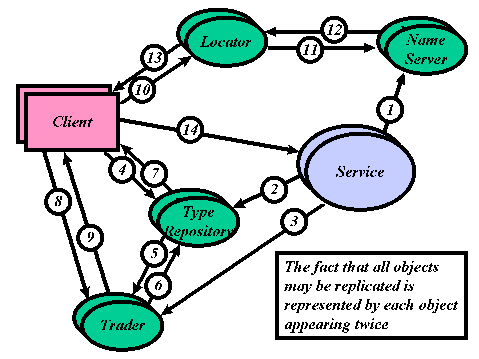
 Figure 1 - Steps in Service Discovery & Access in ODP Reference
Model Terms
Figure 1 - Steps in Service Discovery & Access in ODP Reference
Model TermsTabulated below are the results of an exercise to identify the steps required to discover and access services. They are described in generic terms familiar to those who work in the open distributed systems field, then in Web terms alongside. This provides some insights into how closely the Web can be construed to be compliant with the ODP model. The big assumption (cheat) made, is that systems designed for human as against machine interaction are comparable. If the comparison holds up, it implies (as a generalisation) that the Web is merely deficient in the structure of its data, rather than in its functional elements.
The concepts service, service type, service discovery and service access are used here as defined in Discovery and Access of Services in Globally Distributed Systems, and the type repository function and functions of trading, locating and naming are defined in the ISO/ITU Reference Model for Open Distributed Processing (RM-ODP) which is a framework, defining concepts and functions in open distributed processing.
Figure 1 - Steps in Service Discovery & Access in ODP Reference
Model Terms
(some parts may have to repeat regularly for dynamic services) | |||
| 1 | The service must have its name(s) registered against its address(es) in the name server (pre-supposing allocation of these uniquely) | A name for the service is placed somewhere that potential clients already go (e-mail, Web document) with the URL beneath it (i.e. a hyper-link). | A page of hyper-links is a name-server (albeit unidirectional) and the Web is a massive scale federation of name servers |
| 2 | Type(s) need to be chosen by which it is sensible to classify the service and which are known of by the (extensible) type repository | The service is classified by the provider and gradually by those that use it, usually in their natural language, but also in the classification graphs of popular indexes | Natural language descriptions are a major step towards machine-readable classification systems and point to the need for classification in many alternative contexts |
| 3 | The service needs its name to be registered against the type of service on offer in the trader | hyper-links to the service are gradually placed in popular indexes, in relevant Web pages, news postings and e-mails | The Internet is a massive scale federated trader database from the point of view of services |
| 4, 5, 6, 7 | The client needs to choose a type of service (and possibly properties) which describes what is required and exists in the type repository (which may interact with the trader for sub-types) | The user browses down an index choosing the most likely categories presented or scans the results of a search engine query (a few tries of the links out of the index may be required before a good path is found) | It is impractical to propose global standards for service type definitions. In a massive scale federation the service types can only have meaning within a context that contains that service |
| 8, 9 | The client receives a service name(s) from the trader that best satisfies the requirements description | A resource is found which appears to have the right context and contains a hyper-link with a tempting name | The Web is a massive scale federated trader database from the point of view of clients |
| 10, 11, 12, 13 | The client puts the service name(s) to the locator which interrogates the name server to find the address(es) to which these names map. The locator then decides on the best service address for this particular request and returns it to the client | The hyper-link doesn't directly access the service required, but presents choices of hyper-links with the relative merits of each described. The user chooses the "best" hyper-link (closest, fastest) | Parts of the Web already act as locators (although this is not at all prevalent) |
| 14 | The client uses the address to contact the service | The hyper-link chosen directs the client to the service address underlying it | - |
It can be seen that the Web does indeed contain all the functions that the ODP model would suggest should be present.
 Useful conclusions
can be drawn by considering how it is that one (rather large)
assumption can make the Web nearly conform to the ODP reference
model (in terms of service access and discovery).
Useful conclusions
can be drawn by considering how it is that one (rather large)
assumption can make the Web nearly conform to the ODP reference
model (in terms of service access and discovery).